Projects
This page is a collection of projects that I have worked on. They’re listed here in approximately chronological order, where entries closer to the top are newer and/or more exciting than projects near the bottom.
Data Driven Robotics 2019 – 2024

I have spent the past several years working on data driven robotics. In particular I have focused on addressing challenges that arrise at the intersection of large scale machine learning and real robots.
Working with real hardware that runs in real time in the real world poses a unique set of constraints that are not present in many other areas of machine learning, and my work has focused on developing algorithmic and operational solutions that leverage large scale machine learning to address to these challenges.
My work on data driven robotics falls into four categories.
- Learning from demonstrations
- Reward learning
- Real world evaluation
- Complete agent systems
The first three are fundamental challenges faced when bringing learned policies in the real world. Complete agent systems are projects that aim to synthesize the solutions we have in isolation for the more fundamental problems into complete systems that work together in concert.
Learning from demonstrations
An important challenge in training policies that act in the real world is task specification. How does an agent know what it is supposed to be doing, and how does it recognize when it has done so successfully?
One possible answer to this question is demonstrations. We provide the agent with some examples of correct behavior, and aim to imitate the behavior of those examples in novel settings. In the real world this can be especially challenging due to the fact that many tasks of interest are highly variable and we typically do not have access to a smooth indication of progress to learn from.
With Making Efficient Use of Demonstrations to Solve Hard Exploration Problems we tackled a particularly challenging version of this problem in simulation where we also focused partially observable tasks, requiring the agent to remember information across time in order to complete its task.
- Caglar Gulcehre, Tom Le Paine, Bobak Shahriari, Misha Denil, Matt Hoffman, Hubert Soyer, Richard Tanburn, Steven Kapturowski, Neil Rabinowitz, Duncan Williams, Gabriel Barth-Maron, Ziyu Wang, Nando de Freitas, and The Worlds Team.
Making Efficient Use of Demonstrations to Solve Hard Exploration Problems.
In International Conference on Learning Representations. 2020. [arXiv] [paper] [site]
[bibtex]
@inproceedings{Gulcehre2020a, author = "Gulcehre, Caglar and Paine, Tom Le and Shahriari, Bobak and Denil, Misha and Hoffman, Matt and Soyer, Hubert and Tanburn, Richard and Kapturowski, Steven and Rabinowitz, Neil and Williams, Duncan and Barth-Maron, Gabriel and Wang, Ziyu and de Freitas, Nando and Team, The Worlds", title = "Making Efficient Use of Demonstrations to Solve Hard Exploration Problems", booktitle = "International Conference on Learning Representations", year = "2020", arxiv = "https://arxiv.org/abs/1909.01387", pdf = "https://openreview.net/forum?id=SygKyeHKDH", site = "https://deepmind.google/discover/blog/making-efficient-use-of-demonstrations-to-solve-hard-exploration-problems/" }
In this paper we showed that mixing a small amount of demonstration data with the agent's own self-collected experience was sufficient signal to guide learn eight very difficult long horizon tasks where no other method we tested was able to succeed even a single time.
One challenge of using demonstrations as task specifications is that they both under- and over-constrain the task in different ways. They under-constrain the task by failing to cover all possible initial conditions, and they over constrain the task by specifying states for irrelevant features of the environment. Imagine a demonstration of pouring water with a clock in the background. The demonstration shows what should happen to the water, but also specifies a particular time at which the water should be poured.
In Task-Relevant Adversarial Imitation Learning (TRAIL) we studied a particular solution to the over-specification problem.
- Konrad Żołna, Scott Reed, Alexander Novikov, Sergio Gómez Colmenarejo, David Budden, Serkan Cabi, Misha Denil, Nando de Freitas, and Ziyu Wang.
Task-Relevant Adversarial Imitation Learning.
In Conference on Robot Learning. 2020. [arXiv] [paper]
[bibtex]
@inproceedings{Zolna2020a, author = "Żołna, Konrad and Reed, Scott and Novikov, Alexander and Colmenarejo, Sergio Gómez and Budden, David and Cabi, Serkan and Denil, Misha and de Freitas, Nando and Wang, Ziyu", title = "Task-Relevant Adversarial Imitation Learning", year = "2020", booktitle = "Conference on Robot Learning", pdf = "https://proceedings.mlr.press/v155/zolna21a.html", arxiv = "https://arxiv.org/abs/1910.01077" }
In this paper we show that when using GAIL, a learning from demonstrations method that is particularly prone to locking on to irrelevant details of the demonstrations, we can encourage the model to focus on task relevant features of the problem through a careful choice of regularization for the discriminator.
Another challenge of working with demonstrations is that you need demonstrations for each task of interest, and it is unclear how to exploit demonstrations for one task to improve performance or learning efficiency on other tasks. In Offline Learning from Demonstrations and Unlabeled Experience we extend TRAIL to the offline setting by using demonstrations to learn a reward function (regualrized as in TRAIL) and then apply that reward function to label an offline dataset that includes demonstrations from other tasks.
- Konrad Zolna, Alexander Novikov, Ksenia Konyushkova, Caglar Gulcehre, Ziyu Wang, Yusuf Aytar, Misha Denil, Nando de Freitas, and Scott Reed.
Offline Learning from Demonstrations and Unlabeled Experience.
Technical Report, Deepmind, 2020. [arXiv]
[bibtex]
@techreport{Zolna2020b, author = "Zolna, Konrad and Novikov, Alexander and Konyushkova, Ksenia and Gulcehre, Caglar and Wang, Ziyu and Aytar, Yusuf and Denil, Misha and de Freitas, Nando and Reed, Scott", title = "Offline Learning from Demonstrations and Unlabeled Experience", year = "2020", institution = "Deepmind", arxiv = "https://arxiv.org/abs/2011.13885" }
Reward learning
All GAIL-based learning from demonstrations methods are all built around learning a reward function in a particular way. In addition to the GAIL-based methods discussed above, I have also worked on the problem of learning reward functions directly. Discarding the trappings of GAIL opens up many different possibilities for how to train reward functions and reward functions are useful for many things beyond providing a training signal to agents, so focusing on the reward learning problem on its own has merit.
The motivation of Positive-Unlabeled Reward Learning is very similar to that of Offline Learning from Demonstrations and Unlabeled Experience (and actually predates the latter work, although the final publication date is later). One perspective on PURL is that it fixes an incorrect assumption in GAIL, namely that all the agent generated episodes are worse than all of the demonstrations. If the agent is good then this assumption fails, and this failed assumption is a major source of instability in GAIL. Our offline learning paper addressed this through regularizing the discriminator, while in PURL we approach the problem by removing this problematic assumption.
- Danfei Xu and Misha Denil.
Positive-Unlabeled Reward Learning.
In Conference on Robot Learning. 2021. [arXiv] [paper]
[bibtex]
@inproceedings{Xu2021a, author = "Xu, Danfei and Denil, Misha", title = "Positive-Unlabeled Reward Learning", year = "2021", booktitle = "Conference on Robot Learning", pdf = "https://proceedings.mlr.press/v155/xu21c.html", arxiv = "https://arxiv.org/abs/1911.00459" }
We have also looked at the reward learning problem from the perspective of leveraging the generalization cababilities of modern foundation models to build accurate, robust and universal success detectors. In Vision-language models as success detectors we applied a state of the art (at the time) vision language model to the problem of success detection. The results here are very promising, VLM based success detectors who dramatically improved robustness over baseline models, and this paper also shows the path towards making truly universal, rather than single- or multi-task, reward models.
- Yuqing Du, Ksenia Konyushkova, Misha Denil, Akhil Raju, Jessica Landon, Felix Hill, Nando de Freitas, and Serkan Cabi.
Vision-language models as success detectors.
In Conference on Lifelong Learning Agents. 2023. [arXiv] [paper]
[bibtex]
@inproceedings{Du2023a, author = "Du, Yuqing and Konyushkova, Ksenia and Denil, Misha and Raju, Akhil and Landon, Jessica and Hill, Felix and de Freitas, Nando and Cabi, Serkan", title = "Vision-language models as success detectors", year = "2023", booktitle = "Conference on Lifelong Learning Agents", arxiv = "https://arxiv.org/abs/2303.07280", pdf = "https://proceedings.mlr.press/v232/du23b.html" }
Real world evaluation
When operationalizing trained policies on real robots, one of the key bottlenecks is evaluation. The most consistently effective strategy to improve model perforance across all domains of machine learning is to measure a metric that matters, and then build models that drive that metric up. In robotics, all of those metrics ultimately depend on the real world performance, and measuring real world performance of a policy is time consuming and noisy.
In Active offline policy selection we address the problem of evaluation throughput by modeling our state of knowledge of the entire population of models under consideration. We model our beliefs about the true performance of each model given the evaluations we have observed, as well as correlations between the performance of different models. Quantifying our uncertainty about the performance of each model allows us choose evaluations that will maximize information gain about which model is best, and modeling correlations in performance allows us to use evaluations of one model to inform our performance estimates of others.
- Ksenia Konyushkova, Yutian Chen, Tom Le Paine, Caglar Gulcehre, Cosmin Paduraru, Daniel J Mankowitz, Misha Denil, and Nando de Freitas.
Active Offline Policy Selection.
In Neural Information Processing Systems. 2021. [arXiv] [code] [site]
[bibtex]
@inproceedings{Konyushkova2021a, author = "Konyushkova, Ksenia and Chen, Yutian and Paine, Tom Le and Gulcehre, Caglar and Paduraru, Cosmin and Mankowitz, Daniel J and Denil, Misha and de Freitas, Nando", title = "Active Offline Policy Selection", booktitle = "Neural Information Processing Systems", year = "2021", arxiv = "https://arxiv.org/abs/2106.10251", code = "https://github.com/google-deepmind/active_ops", site = "https://deepmind.google/discover/blog/active-offline-policy-selection/" }
One of the key challenges in the AOPS paper was determining a good way to measure the similarity of different policies. We used a simple method of featurizing policies in the AOPS paper that works well when the policies are very similar, and in our followup work $\pi$2vec we developed a more complex method that works better than the AOPS featurization strategy when the policies are more different.
- Gianluca Scarpellini, Ksenia Konyushkova, Claudio Fantacci, Tom Le Paine, Yutian Chen, and Misha Denil.
𝜋2vec: Policy Representations with Successor Features.
In International Conference on Learning Representations. 2024. [arXiv] [paper]
[bibtex]
@inproceedings{Scarpellini2024a, author = "Scarpellini, Gianluca and Konyushkova, Ksenia and Fantacci, Claudio and Paine, Tom Le and Chen, Yutian and Denil, Misha", title = "𝜋2vec: Policy Representations with Successor Features", year = "2024", booktitle = "International Conference on Learning Representations", arxiv = "https://arxiv.org/abs/2306.09800", pdf = "https://openreview.net/forum?id=o5Bqa4o5Mi" }
Accurate, sound and efficient evaluation is a deep problem, and my public works only scratch the surface of this important topic.
Complete agent systems
My earliest works in this area is Scaling data-driven robotics with reward sketching and batch reinforcement learning. This paper presents a complete end to end agent system, and laid the foundations for many of the works that followed. This paper was one of the first to show that learned rewards can be used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We showed that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
- Serkan Cabi, Sergio Gómez Colmenarejo, Alexander Novikov, Ksenia Konyushkova, Scott Reed, Rae Jeong, Konrad Żołna, Yusuf Aytar, David Budden, Mel Vecerik, Oleg Sushkov, David Barker, Jonathan Scholz, Misha Denil, Nando de Freitas, and Ziyu Wang.
Scaling data-driven robotics with reward sketching and batch reinforcement learning.
In Robotics, Science and Systems. 2020. [arXiv] [paper] [code] [site]
[bibtex]
@inproceedings{Cabi2020a, author = "Cabi, Serkan and Colmenarejo, Sergio Gómez and Novikov, Alexander and Konyushkova, Ksenia and Reed, Scott and Jeong, Rae and Żołna, Konrad and Aytar, Yusuf and Budden, David and Vecerik, Mel and Sushkov, Oleg and Barker, David and Scholz, Jonathan and Denil, Misha and de Freitas, Nando and Wang, Ziyu", title = "Scaling data-driven robotics with reward sketching and batch reinforcement learning", booktitle = "Robotics, Science and Systems", year = "2020", arxiv = "https://arxiv.org/abs/1909.12200", pdf = "https://roboticsconference.org/2020/program/papers/76.html", site = "https://sites.google.com/view/data-driven-robotics/", code = "https://github.com/google-deepmind/deepmind-research/tree/master/sketchy" }
Many of the ideas originally developed in this paper can be seen operating in more refined forms, and at much larger scale, in RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation.
- Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X Lee, Maria Bauza, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, Antoine Laurens, Claudio Fantacci, Valentin Dalibard, Martina Zambelli, Murilo Martins, Rugile Pevceviciute, Michiel Blokzijl, Misha Denil, Nathan Batchelor, Thomas Lampe, Emilio Parisotto, Konrad Żołna, Scott Reed, Sergio Gómez Colmenarejo, Jon Scholz, Abbas Abdolmaleki, Oliver Groth, Jean-Baptiste Regli, Oleg Sushkov, Tom Rothörl, José Enrique Chen, Yusuf Aytar, Dave Barker, Joy Ortiz, Martin Riedmiller, Jost Tobias Springenberg, Raia Hadsell, Francesco Nori, and Nicolas Heess.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation.
Transactions on Machine Learning Research, 2023. [arXiv] [paper] [site]
[bibtex]
@article{Bousmalis2023a, author = "Bousmalis, Konstantinos and Vezzani, Giulia and Rao, Dushyant and Devin, Coline and Lee, Alex X and Bauza, Maria and Davchev, Todor and Zhou, Yuxiang and Gupta, Agrim and Raju, Akhil and Laurens, Antoine and Fantacci, Claudio and Dalibard, Valentin and Zambelli, Martina and Martins, Murilo and Pevceviciute, Rugile and Blokzijl, Michiel and Denil, Misha and Batchelor, Nathan and Lampe, Thomas and Parisotto, Emilio and Żołna, Konrad and Reed, Scott and Colmenarejo, Sergio Gómez and Scholz, Jon and Abdolmaleki, Abbas and Groth, Oliver and Regli, Jean-Baptiste and Sushkov, Oleg and Rothörl, Tom and Chen, José Enrique and Aytar, Yusuf and Barker, Dave and Ortiz, Joy and Riedmiller, Martin and Springenberg, Jost Tobias and Hadsell, Raia and Nori, Francesco and Heess, Nicolas", title = "RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation", year = "2023", journal = "Transactions on Machine Learning Research", arxiv = "https://arxiv.org/abs/2306.11706", site = "https://deepmind.google/discover/blog/robocat-a-self-improving-robotic-agent/", pdf = "https://openreview.net/forum?id=vsCpILiWHu" }
Learning to Learn 2016 – 2017
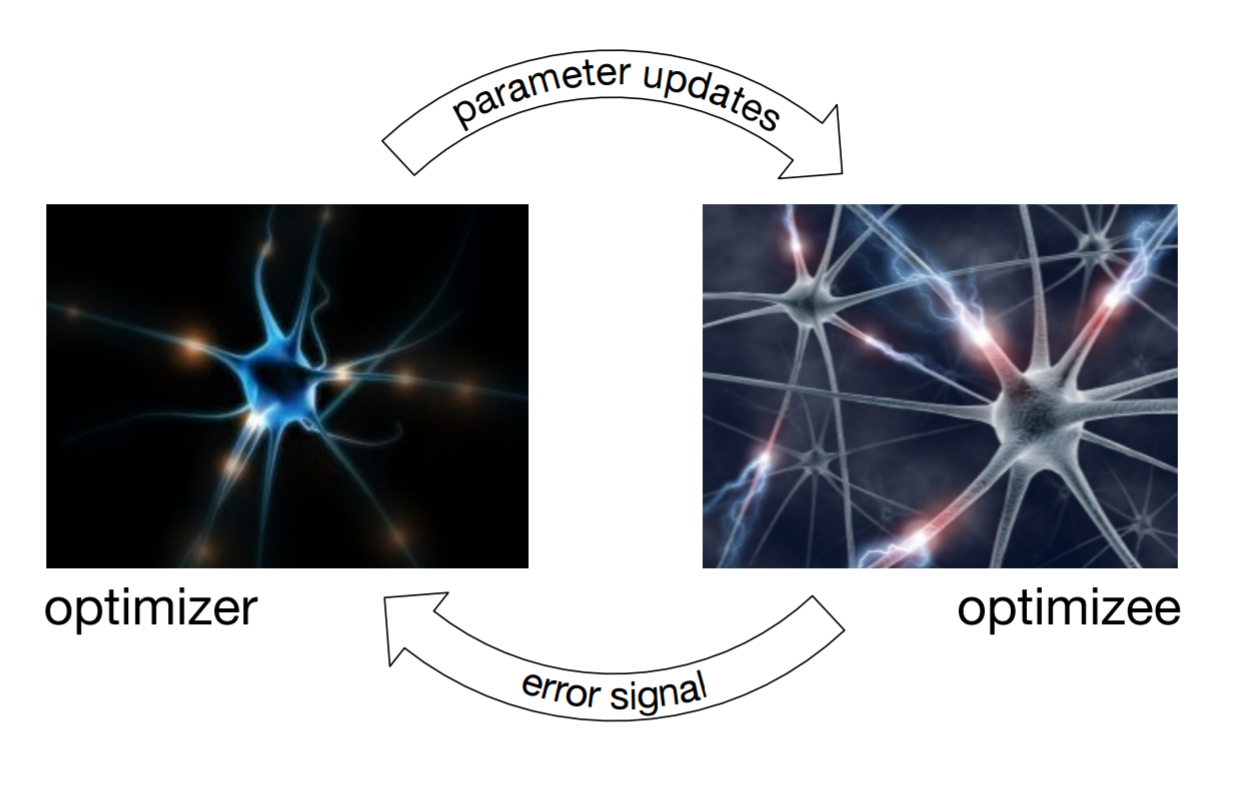
Much of the modern work in optimization is based around designing update rules tailored to specific classes of problems, with the types of problems of interest differing between different research communities. For example, in the deep learning community we have seen a proliferation of optimization methods specialized for high-dimensional, non-convex optimization problems. In contrast, communities who focus on sparsity tend to favour very different approaches, and this is even more the case for combinatorial optimization for which relaxations are often the norm.
Each of these communities make different assumptions about their problems of interest. In nearly every case, when more is known about the target problem then more focused methods can be developed to exploit these structural regularities.
Instead of characterising structural regularities mathematically we can treat their identification as a learning problem, and train models which learn about the model learning process itself.
We applied this insight to learning update rules for gradient based optimization using recurrent neural networks.
- Marcin Andrychowicz, Misha Denil, Sergio Gómez Colmenarejo, Matthew W. Hoffman, David Pfau, Tom Schaul, and Nando de Freitas.
Learning to Learn by Gradient Descent by Gradient Descent.
In Neural Information Processing Systems. 2016. [arXiv] [code] [project]
[bibtex]
@inproceedings{Andrychowicz2016a, author = "Andrychowicz, Marcin and Denil, Misha and Colmenarejo, Sergio Gómez and Hoffman, Matthew W. and Pfau, David and Schaul, Tom and de Freitas, Nando", title = "Learning to Learn by Gradient Descent by Gradient Descent", year = "2016", booktitle = "Neural Information Processing Systems", project = "learning-to-learn", arxiv = "https://arxiv.org/abs/1606.04474", code = "https://github.com/google-deepmind/learning-to-learn" }
We have code for training optimizers available on github.
This works surprisingly well more or less out of the box, with two weaknesses. The trained optimizer has a fairly high memory overhead, and generalising to new problems does not always work reliably. We explored these problems in some detail, and found that the generalisation properties of our learned optimizers could be greatly improved through careful design of the model and training procedure.
- Olga Wichrowska, Niru Maheswaranathan, Matthew W. Hoffman, Sergio Gómez Colmenarejo, Misha Denil, Nando de Freitas, and Jascha Sohl-Dickstein.
Learned Optimizers that Scale and Generalize.
In International Conference on Machine Learning. 2017. [arXiv] [project]
[bibtex]
@inproceedings{Wichrowska2017a, author = "Wichrowska, Olga and Maheswaranathan, Niru and Hoffman, Matthew W. and Colmenarejo, Sergio Gómez and Denil, Misha and de Freitas, Nando and Sohl-Dickstein, Jascha", title = "Learned Optimizers that Scale and Generalize", year = "2017", booktitle = "International Conference on Machine Learning", project = "learning-to-learn", arxiv = "https://arxiv.org/abs/1703.04813" }
In addition to learning gradient based updates, we have also looked at learning global optimizers. Here the challenges are different than with gradient based methods, and we show how to design supervised objectives to explicitly encourage the optimizer to explore the search space. We also show how to exploit gradients at training time in order to learn optimizers that operate gradient free at test time.
- Yutian Chen, Matthew W. Hoffman, Sergio Gómez Colmenarejo, Misha Denil, Timothy P. Lillicrap, and Nando de Freitas.
Learning to Learn for Global Optimization of Black Box Functions.
In International Conference on Machine Learning. 2017. [arXiv] [project]
[bibtex]
@inproceedings{Chen2017a, author = "Chen, Yutian and Hoffman, Matthew W. and Colmenarejo, Sergio Gómez and Denil, Misha and Lillicrap, Timothy P. and de Freitas, Nando", title = "Learning to Learn for Global Optimization of Black Box Functions", year = "2017", booktitle = "International Conference on Machine Learning", project = "learning-to-learn", arxiv = "https://arxiv.org/abs/1611.03824" }
Learning to Experiment 2016
When encountering novel objects, humans are able to infer a wide range of physical properties such as mass, friction and deformability by interacting with them in a goal driven way. This process of active interaction is in the same spirit of a scientist performing an experiment to discover hidden facts.
Recent advances in artificial intelligence have yielded machines that can achieve superhuman performance in Go, Atari, natural language processing, and complex control problems, but it is not clear that these systems can rival the scientific intuition of even a young child.
We introduce two tasks that require require agents to interact with the world in order to identify some non-visual physical property of the objects it contains. In the first environment the agents must poke blocks in order to determine which of them is the heaviest, and in the second enviornment agents must knock down block towers and count the number of rigid bodies they are composed of.
- Misha Denil, Pulkit Agrawal, Tejas D Kulkarni, Tom Erez, Peter Battaglia, and Nando de Freitas.
Learning to Perform Physics Experiments via Deep Reinforcement Learning.
In International Conference on Learning Representations. 2017. [arXiv] [paper] [project]
[bibtex]
@inproceedings{Denil2017a, author = "Denil, Misha and Agrawal, Pulkit and Kulkarni, Tejas D and Erez, Tom and Battaglia, Peter and de Freitas, Nando", title = "Learning to Perform Physics Experiments via Deep Reinforcement Learning", year = "2017", booktitle = "International Conference on Learning Representations", pdf = "http://openreview.net/forum?id=r1nTpv9eg", project = "learning-to-experiment", arxiv = "https://arxiv.org/abs/1611.01843" }
Several news sites have written nice articles about this work for a general audience.
Predicting Parameters in Deep Learning 2013 – 2016
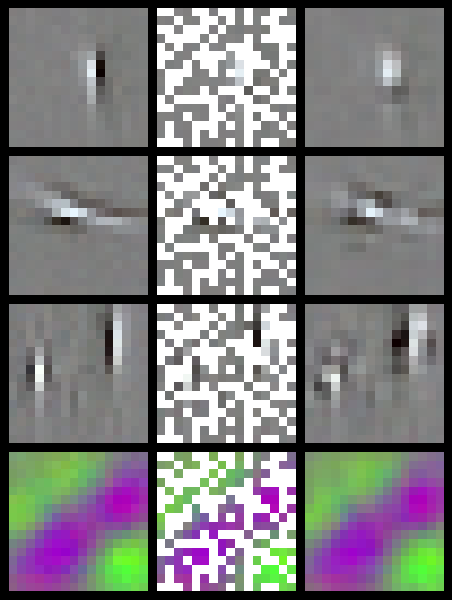

It is well known that the first layer features in many deep learning architectures tend to be globally smooth with local edge features, similar to local Gabor functions, when trained on natural images. We show that it is possible to exploit the redundancy in this type of structure when learning neural nets.
Our key innovation is to store explicit values for only a sparse subset of the weights in each feature, and predict the remaining values using ridge regression. By representing only a small number of weights explicitly we are able to dramatically reduce the number of parameters which must be learned. In the best case we are able to predict more than 95% of the parameters in a network without any drop in accuracy.
Our technique is very general, and can be applied to almost any neural network model; it is also orthogonal but complementary to other recent advances in deep learning, such as dropout, rectified units and maxout.
Reducing the number of learned parameters could also be of great benefit in distributed settings. The bottleneck in large scale distributed learning of neural networks is the cost of synchronizing parameter updates between machines. If fewer parameters need to be learned then this burden can be reduced.
- Misha Denil, Babak Shakibi, Laurent Dinh, Marc’Aurelio Ranzato, and Nando de Freitas.
Predicting Parameters in Deep Learning.
In Neural Information Processing Systems. 2013. [paper] [poster] [project]
[bibtex]
@inproceedings{Denil2013b, author = "Denil, Misha and Shakibi, Babak and Dinh, Laurent and Ranzato, Marc’Aurelio and de Freitas, Nando", title = "Predicting Parameters in Deep Learning", year = "2013", booktitle = "Neural Information Processing Systems", pdf = "http://papers.nips.cc/paper/5025-predicting-parameters-in-deep-learning", project = "parameter-prediction", poster = "2013-predicting-parameters-poster-mdenil.pdf" }
I also presented this work in the ICML 2013 Challenges in Representation Learning Workshop.
Feb 2014: Our lab received a Google research award to continue this work.
We applied the predicting parameters idea to reducing the memory footprint of a standard convolutional network (eg., AlexNet). In particular, we show how the fully connected layers can be replaced with a randomized kernel machine. This transformation is efficient in terms of both memory and computation, and importantly we can learn the parameters of the kernel transformation jointly with the parameters of the convolutional layers of the network.
A major drawback of the Deep Fried approach is that the randomized kernel machine requires a lot of features in order to work well. The feature mapping itself is efficient, but the high dimensionality introduces a lot of parameters into the final softmax layer, which has had its input dimensionality increased.
To correct this drawback we can make the network deep instead of wide. We designed a new layer composed of diagonal matrices and cosine transforms which can be stacked to form very deep hierarchies which we call ACDC. From a high level ACDC is similar to the Deep Fried layer, but the construction is simplified and the interpretation as a kernel machine is abandoned.
Deep Learning for Natural Language Processing 2014 – 2015

Capturing the compositional process which maps the meaning of words to that of documents is a central challenge for researchers in Natural Language Processing and Information Retrieval. We introduce a model that is able to represent the meaning of documents by embedding them in a low dimensional vector space, while preserving distinctions of word and sentence order crucial for capturing nuanced semantics.
Our model learns convolution filters at both the sentence and document level, hierarchically learning to capture and compose low level lexical features into high level semantic concepts.
Inspired by recent advances in visualising deep convolution networks for computer vision, we present a novel visualisation technique for our document networks which not only provides insight into their learning process, but also can be interpreted to produce a compelling automatic summarisation system for texts.
- Misha Denil, Alban Demiraj, and Nando de Freitas.
Extraction of Salient Sentences from Labelled Documents.
Technical Report, University of Oxford, 2014. [arXiv] [code] [project]
[bibtex]
@techreport{Denil2014b, author = "Denil, Misha and Demiraj, Alban and de Freitas, Nando", title = "Extraction of Salient Sentences from Labelled Documents", year = "2014", arxiv = "http://arxiv.org/abs/1412.6815", institution = "University of Oxford", code = "https://github.com/mdenil/txtnets", project = "deep-nlp" }
The code for this paper is available on github.
An interesting property of our deep convolutional document model is that it simultaneously produces embeddings for words, sentences and documents using labels only at the document level. We exploit this to develop a new approach to training a sentence classifier by using the sentence embeddings from the document model as a similarity measure. Our approach, which combines ideas from transfer learning, deep learning and multi-instance learning, reduces the need for laborious human labelling of sentences when abundant document labels are available.
- Dimitrios Kotzias, Misha Denil, Nando de Freitas, and Padhraic Smyth.
From Group to Individual Labels using Deep Features.
In ACM SIGKDD. 2015. [paper] [poster] [project]
[bibtex]
@inproceedings{Kotzias2015a, author = "Kotzias, Dimitrios and Denil, Misha and de Freitas, Nando and Smyth, Padhraic", title = "From Group to Individual Labels using Deep Features", year = "2015", booktitle = "ACM SIGKDD", project = "deep-nlp", pdf = "/static/papers/2015-deep-multi-instance-learning.pdf", poster = "2015-group-to-individual-labels-using-deep-features-poster.pdf" }
Dimitros Kotzias has more information about our multi-instance learning work on his website.
Consistency of Random Forests 2013 – 2014

Random forests are a popular classification algorithm, originally developed by Leo Breiman in the early 2000's. While this algorithm has been extremely successful in practice, relatively little is known about the underlying mathematical forces which drive this success.
We have been working on narrowing the gap between the theory and practice of random forests. To this end we have designed a variant of random regression forests which achieves the closest match to date between theoretically tractable models and what is actually used in practice. This match is achieved both in terms of similarity of the algorithms and in terms of performance on real world tasks.
Our work also shows empirically that data splitting, a simplification made by recent theoretical works on random forests, is responsible for nearly all of the remaining performance gap between the theoretically tractable models and their more practical counterparts.
- Misha Denil, David Matheson, and Nando de Freitas.
Narrowing the Gap: Random Forests In Theory and In Practice.
In International Conference on Machine Learning. 2014. [arXiv] [paper] [poster] [project]
[bibtex]
@inproceedings{Denil2014a, author = "Denil, Misha and Matheson, David and de Freitas, Nando", title = "Narrowing the Gap: Random Forests In Theory and In Practice", year = "2014", booktitle = "International Conference on Machine Learning", poster = "2014-rf-theory-practice-icml-poster.pdf", arxiv = "http://arxiv.org/abs/1310.1415", pdf = "http://jmlr.org/proceedings/papers/v32/denil14.html", project = "random-forests" }
We have also looked at the problem of training random forests in an online setting. The main limitation of online tree building algorithms is memory. Because the trees are built online they must be built depth first. Collecting statistics in the fringe becomes very expensive in large trees. We work around this by limiting the number leafs permitted to be “active” at any time, which allows us to control the amount of memory used to store the fringe. Our analysis shows that the algorithm is still consistent when this refinement is included.
Our consistent algorithm compares favourably to an existing online random forest algorithm on a simple problem, and outperforms it on a more realistic task.
- Misha Denil, David Matheson, and Nando de Freitas.
Consistency of Online Random Forests.
In International Conference on Machine Learning. 2013. [arXiv] [paper] [poster] [project]
[bibtex]
@inproceedings{Denil2013a, author = "Denil, Misha and Matheson, David and de Freitas, Nando", title = "Consistency of Online Random Forests", year = "2013", booktitle = "International Conference on Machine Learning", arxiv = "http://arxiv.org/abs/1302.4853", poster = "2013-online_random_forests-icml-poster.pdf", pdf = "http://jmlr.org/proceedings/papers/v28/denil13.html", project = "random-forests" }
The code for this paper is available on github. You can also download the kinect data we used in the experiments.
Distributed Composite Likelihood 2014
This work lays out the theoretical foundations for distributed parameter estimation in Markov Random Fields. We take a composite likelihood approach, which allows us to distribute sub-problems across machines to be solved in parallel. We provide a general condition on composite likelihood factorisations which ensures that the distributed estimators are consistent.
- Yariv Dror Mizrahi, Misha Denil, and Nando de Freitas.
Distributed Parameter Estimation in Probabilistic Graphical Models.
In Neural Information Processing Systems. 2014. [arXiv] [poster] [project]
[bibtex]
@inproceedings{Mizrahi2014b, author = "Mizrahi, Yariv Dror and Denil, Misha and de Freitas, Nando", title = "Distributed Parameter Estimation in Probabilistic Graphical Models", year = "2014", booktitle = "Neural Information Processing Systems", arxiv = "http://arxiv.org/abs/1406.3070", poster = "2014-lap-nips-poster.pdf", project = "lap" }
Our work on composite likelihood grew out of our work on the LAP algorithm, which can be seen a a specific instantiation of the distributed composite likelihood framework.
- Yariv Dror Mizrahi, Misha Denil, and Nando de Freitas.
Linear and Parallel Learning of Markov Random Fields.
In International Conference on Machine Learning. 2014. [arXiv] [project]
[bibtex]
@inproceedings{Mizrahi2014a, author = "Mizrahi, Yariv Dror and Denil, Misha and de Freitas, Nando", title = "Linear and Parallel Learning of Markov Random Fields", year = "2014", booktitle = "International Conference on Machine Learning", arxiv = "http://arxiv.org/abs/1308.6342", project = "lap" }
Recklessly Approximate Sparse Coding 2012
The introduction of “k-means” features by Coates et al., along with their later refinement into soft threshold features by the same authors, caused considerable discussion in the deep learning community. These very simple and efficiently computed features were shown to achieve state of the art performance on several image classification tasks, beating out a variety of more sophisticated feature learning techniques.
The purpose of this work is to provide a theoretical explanation for the surprising efficacy of these feature encodings. This explanation is realized by a formal connection between the design of the soft threshold features and an approximate solution to a non-negative sparse coding problem using proximal gradient descent.
- Misha Denil and Nando de Freitas.
Recklessly Approximate Sparse Coding.
Technical Report, University of British Columbia, 2012. [arXiv] [project]
[bibtex]
@techreport{Denil2012b, author = "Denil, Misha and de Freitas, Nando", title = "Recklessly Approximate Sparse Coding", institution = "University of British Columbia", year = "2012", arxiv = "http://arxiv.org/abs/1208.0959", project = "approximate-sparse-coding" }
Quantum Deep Learning 2011
I spent the summer of 2011 as an intern in the applications group at D-Wave Systems. D-Wave is a company whose flagship product is a quantum computer which they have designed and built.
While I was at D-Wave I worked on applying their quantum computer to deep learning problems. There are a lot of interesting challenges in this area, both in terms of finding ways express problems in terms which the machine can handle, and in terms of dealing with the idiosyncrasies of what is still very new technology.
The result of this project was a paper in the 2011 NIPS Deep Learning Workshop where we presented an algorithm for training RBMs with lateral connections using the quantum computer. The algorithm itself is sound (in the sense that it works in software), but unfortunately practical issues prevent it from working in vivo. The the main difficulty is that the algorithm requires the ability to set parameters on the machine with much higher precision than the hardware was able to support. However, the algorithm may become feasible on future generations of hardware.
- Misha Denil and Nando de Freitas.
Toward the Implementation of a Quantum RBM.
In NIPS Deep Learning and Unsupervised Feature Learning Workshop. 2011. [paper] [poster] [project]
[bibtex]
@inproceedings{Denil2011b, author = "Denil, Misha and de Freitas, Nando", title = "Toward the Implementation of a Quantum RBM", year = "2011", booktitle = "NIPS Deep Learning and Unsupervised Feature Learning Workshop", project = "quantum-deep-learning", poster = "2011-quantum-deep-learning-poster-mdenil.pdf", pdf = "/static/papers/2011-mdenil-quantum_deep_learning-nips_workshop.pdf" }
Gaze Selection for Object Tracking in Video 2011

My involvement in this project began as project for a machine learning course I took in the winter semester of the 2010-2011 school year. The larger goal is to build an object tracking system inspired by the human visual system.
My contribution was to build a model for gaze selection (that is, a control mechanism for saccades). During tracking the system maintains a template of the target object being tracked and at each time step it selects a small sub-region of the template to compare with its estimated location in the frame. I built a model to decide which sub-region of the template to select for comparison at each time step.
- Misha Denil, Loris Bazzani, Hugo Larochelle, and Nando de Freitas.
Learning where to Attend with Deep Architectures for Image Tracking.
Neural Computation, 2012. [arXiv] [paper] [code] [project]
[bibtex]
@article{Denil2012a, author = "Denil, Misha and Bazzani, Loris and Larochelle, Hugo and de Freitas, Nando", title = "Learning where to Attend with Deep Architectures for Image Tracking", journal = "Neural Computation", year = "2012", arxiv = "http://arxiv.org/abs/1109.3737", pdf = "http://www.mitpressjournals.org/doi/abs/10.1162/NECO_a_00312", code = "http://www.cs.ox.ac.uk/people/misha.denil/projects/gaze_selection_for_object_tracking/bayesopt_tracker_10-27-2011.tar.bz2", project = "gaze-selection" } - My project report gives a much shorter description of the model and focuses specifically on my contribution.
- The source code is available for download. It’s a large file because the archive includes several trained models needed for actually running the system.